組織に眠る知識を「見える化」する!RAGで実現する知識の可視化と活用
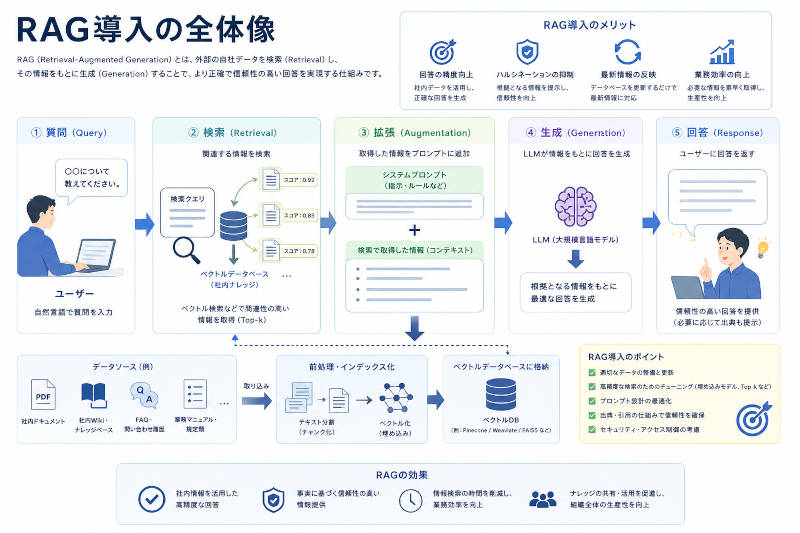
「あの情報、どこかにあるはずなんだけど誰も知らない」「部署をまたいで情報を探すと、たらい回しになる」「優秀な人が退職したら、その人の持っていた知識が組織から消えてしまった」——こうした状況に心当たりのある方は多いのではないでしょうか。
組織の知識は、確かに存在しています。しかし、部署ごとに分断され・個人の頭の中に閉じ込められ・バラバラな形式で保存されているために、必要なときに必要な人が使えない状態になっています。
RAGはこの「見えない知識」を可視化し、組織全体で活用できる資産へと転換する技術です。本記事では、組織知識の可視化にRAGがどのように貢献するかを解説します。
サイロ解消と文書統合:分断された知識を一つにつなぐ
組織における知識の最大の敵は「サイロ」です。部署・チーム・システムごとに情報が孤立し、他から参照・活用できない状態は、組織が大きくなるほど深刻化します。
- サイロ:部署・チーム・システムごとに情報や知識が孤立し、組織横断での共有・参照が困難になっている状態。縦割り組織構造や、異なるツール・フォーマットの乱立によって生じることが多い。
- 文書統合:部署・システム・フォーマットを問わず、組織内に分散する文書・データ・記録を単一のナレッジベースに集約し、横断的に検索・参照できる状態にすること。
現実の組織では、知識が以下のような形で分散しています。
- 営業部門:CRMの商談記録・提案書・顧客対応メール
- 開発部門:設計書・コードコメント・障害対応ログ
- 人事部門:採用基準・評価記録・研修資料
- 経営企画:市場調査レポート・議事録・中期計画
これらがサイロ化している限り、「営業が持つ顧客課題の情報を開発が製品改善に活かす」「人事の採用基準と現場の評価観点を統一する」といった横断的な知識活用は実現しません。
RAGによる文書統合では、ファイル形式(Word・PDF・Excel・Markdown)やシステム(SharePoint・Confluence・Notion・Google Drive)の違いを吸収しながら、すべての文書をベクトル化してひとつのナレッジベースに集約します。物理的に異なる場所に保存されたままでも、RAGが横断的に参照できる「論理的な統合」が実現します。
サイロ解消の本質は、情報の「所有権」を部署から組織全体へと開放することにあります。RAGはその技術的な橋渡し役を担います。
ナレッジグラフと関連性抽出:知識のつながりを可視化する

文書を集めてベクトル化するだけでは、「点」としての知識の検索は可能になりますが、「知識同士のつながり」は見えないままです。RAGを発展させた知識管理において、次の段階として重要になるのがナレッジグラフと関連性抽出です。
- ナレッジグラフ:組織内の人・プロジェクト・文書・概念・出来事などを「ノード(点)」として定義し、それらの間の関係性を「エッジ(線)」でつないだ構造化された知識の地図。「誰が何を知っているか」「どのプロジェクトがどの技術と関係しているか」を視覚的・構造的に把握できる。
- 関連性抽出:文書・データ・記録の中から、人名・組織名・概念・日時・出来事などの要素を特定し、それらの間にある意味的な関係性(因果・所属・参照・類似など)を自動的に抽出すること。
ナレッジグラフをRAGと組み合わせることで、検索の精度と深みが大きく向上します。
通常のベクトル検索では「この文書が質問と意味的に近い」という判断しかできません。しかしナレッジグラフと組み合わせることで、「この文書に登場するプロジェクトXは、技術Yと関係があり、担当者Aが携わっており、過去の障害事例Zとも関連している」という多段的なつながりを辿った検索が可能になります。
関連性抽出の具体的な活用例を挙げます。
① 専門知識の所在マップ
社内文書から「誰がどのテーマに関する文書を多く作成・参照しているか」を抽出することで、「この領域の知識エキスパートは誰か」を組織全体で可視化できます。属人的だった専門知識の所在が、システムによって明示されます。
② プロジェクト間の知識連鎖
「プロジェクトAで培った技術がプロジェクトCにも応用できる」という関連性を、担当者が気づく前にナレッジグラフが示してくれます。組織内での知識の再利用率が高まります。
③ リスクの連鎖把握
「この規制変更が影響する業務プロセスは何か」「その業務に関連する契約書や担当部署はどこか」という影響の連鎖を、ナレッジグラフが構造的に追跡します。
検索性向上:「探せる組織」が持つ圧倒的な競争優位
知識を統合・可視化しても、必要なときに必要な人が素早く見つけられなければ意味がありません。RAGによる組織知識の可視化の最終的な価値は「検索性の向上」という形で日常業務に現れます。
- 検索性向上:組織内の情報・文書・知識を、必要な人が必要なタイミングで、最小限の手間で見つけられる状態を実現すること。キーワードの完全一致だけでなく、意味・文脈・関連性による探索が可能になることで、情報の発見可能性が根本から改善される。
検索性が低い組織では、以下のような問題が日常的に発生しています。
- 同じ資料を複数の人が別々に作成する重複作業
- 「誰かが知っているはずだが誰に聞けばいいかわからない」という迷子状態
- 「前回の提案書を参考にしたいが見つからない」という資産の死蔵
RAGによる検索性向上は、これらの問題をいくつかのアプローチで解消します。
① 自然言語による検索
「去年の夏に実施したキャンペーンの費用対効果に関する資料」という曖昧で自然な表現でも、RAGがベクトル検索によって意味的に近い文書を特定します。正確なファイル名やキーワードを覚えていなくても情報にたどり着けます。
② 文脈を考慮した検索結果の提示
単純に類似文書を列挙するのではなく、「質問の意図に最も適した情報はどれか」という文脈判断をRAGが行い、ランキングして提示します。大量の検索結果から目的のものを探し直す手間が省けます。
③ 関連情報の芋づる式提示
ひとつの情報を取得した際に、「これに関連する文書・担当者・過去事例」も合わせて提示することで、一度の検索で周辺情報まで把握できます。情報収集の効率が飛躍的に向上します。
検索性が高い組織は、意思決定が速く・重複作業が少なく・知識の継承が途切れません。RAGによる検索性向上は、組織の生産性を底上げする基盤インフラとなります。
この記事のまとめ
組織知識の可視化は、「知識を作ること」ではなく「すでに存在する知識を使えるようにすること」です。RAGはその実現を技術的に支える中核となります。
| 観点 | 得られる効果 |
|---|---|
| サイロ解消 × 文書統合 | 部署・システム・形式を超えて知識を一元化し横断活用を実現 |
| ナレッジグラフ × 関連性抽出 | 知識同士のつながりを可視化し、多段的な探索と再利用を促進 |
| 検索性向上 | 自然言語と文脈で情報にたどり着き、重複作業と情報迷子を解消 |
組織に蓄積された知識は、適切に可視化・構造化されて初めて「競争優位の源泉」となります。RAGはその可視化を継続的に実現し続けるための仕組みです。
まずは最も情報の迷子が起きやすい部署・業務領域を特定し、そこから文書統合とナレッジベースの構築を始めることをお勧めします。小さく始めた「見える化」が、やがて組織全体の知識活用文化を変えていきます。
RAG導入専門:語彙辞典
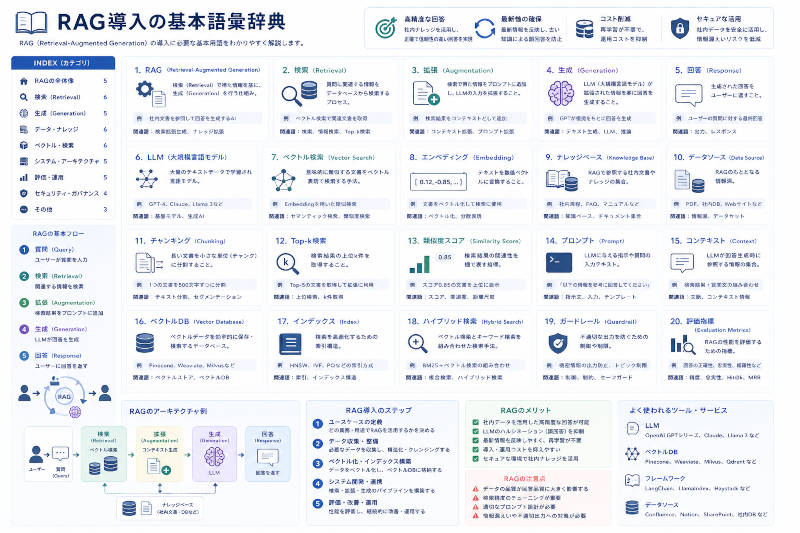
以下に、RAG(検索拡張生成)の導入を通じて、企業内に分散・埋没している膨大なデータやノウハウ(組織知識)を洗い出し、組織全体の「どこに、どんな知識があるか」を透明化・資産化するための重要キーワードとその簡潔な意味を一覧で示します。
■ 1. 散在するナレッジの網羅的把握(知識の棚卸し)
・データサイロ(Data Silo):部門ごと、あるいはシステム(SharePoint、Salesforce、Google Driveなど)ごとに情報が孤立し、他部署から検索・活用できない状態のこと。
・ダークデータ(Dark Data):日報、議事録、古いPDFなど、社内に蓄積されているものの、活用されず眠ったままになっている未構造化データのこと。
・ナレッジマッピング(Knowledge Mapping):組織内に存在するドキュメントやベテラン社員のノウハウを洗い出し、それらの関係性や所在を体系的に整理・可視化すること。
■ 2. ベクトル空間による知の構造化(意味の可視化)
・ベクトル空間(Vector Space):埋め込みモデルによって、社内すべての文章(チャンク)を「意味の近さ」に基づいて配置した仮想的な多次元空間。
・クラスタリング(Clustering):ベクトル空間上で、意味やテーマが似ている社内文書をAIが自動的にグループ分けし、どんなテーマの知識が多いかを可視化する技術。
・知識のギャップ分析(Knowledge Gap Analysis):RAGの検索ログ(ユーザーの質問)と社内ナレッジの分布を比較し、「社員が求めているのに、社内文書として存在しない知識領域」を特定する手法。
■ 3. 組織のつながりと情報流動の可視化
・エキスパート検索(Expert Finder):RAGのシステムを通じて、特定の技術や業務に最も詳しい社員(過去にそのテーマの報告書を多く書いている人など)を自動で特定・可視化する仕組み。
・ナレッジグラフ(Knowledge Graph):「人」「プロジェクト」「技術」「文書」などの社内要素を線(データリンク)で結び、組織内の知識がどのように関連し合っているかを網羅的に表した図。
・情報鮮度インジケーター(Content Freshness Indicator):ナレッジベース内の各文書がいつ作成・更新されたかを可視化し、組織の知識が陳腐化(形骸化)していないかをチェックする指標。
■ 4. 利活用状況のモニタリング(組織知の活性化)
・検索クエリ分析(Search Query Analytics):社員が日々の業務で「どのようなキーワードや課題」を多く検索しているかを可視化し、組織全体の今の関心事やボトルネックを把握すること。
・ナレッジ貢献度評価(Knowledge Contribution):どの部署の、どの文書がRAGの回答に多く引用(グラウンディング)され、業務効率化に貢献したかを数値化・可視化する仕組み。
・未解決クエリ(Unanswered Queries):社員がRAGに質問したものの、社内に適切なドキュメントがないため「AIが回答できなかった質問」の履歴。優先的に作成すべきマニュアルのリストとして可視化される。