社内の知識を”使える資産”に変える!ナレッジ活用最適化の実践
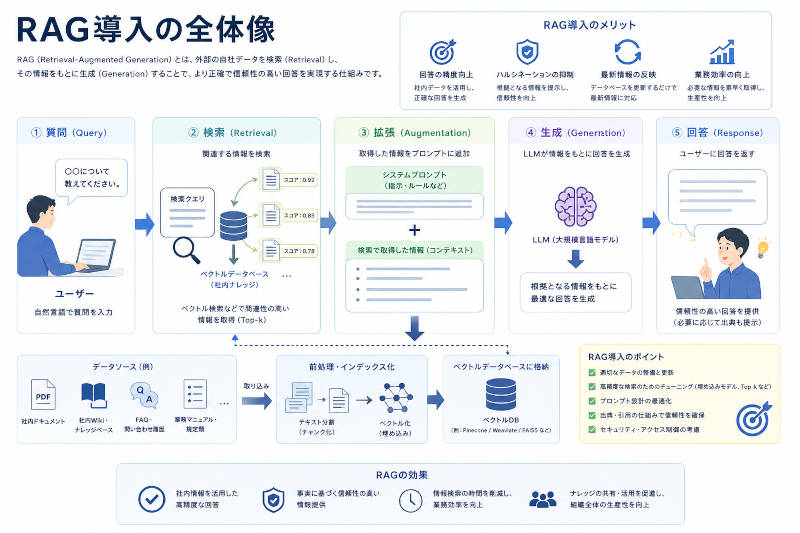
「社内にはたくさんの文書があるのに、必要な情報がすぐに見つからない」「FAQを作ったはいいが、いつの間にか情報が古くなっている」——多くの組織が抱えるこの悩み、RAGを活用することで根本から解決できます。
RAGの真価は、単に外部情報をAIに渡すことではなく、組織固有の知識を”検索可能な資産”として整備し、継続的に活用し続ける仕組みを作ることにあります。
本記事では、ナレッジ活用を最適化するための核心的な考え方と実践手法を解説します。
社内文書とFAQ統合:バラバラな知識を一元化する
多くの組織では、知識が以下のように分散しています。
- 部署ごとのマニュアルや規定集(Word・PDF)
- 過去のQ&A対応メール
- 社内Wikiや議事録
- 顧客からのよくある質問リスト
これらをRAGに取り込む際に重要なのが、社内文書とFAQ統合の考え方です。
- 社内文書:組織内で蓄積されたマニュアル・規定・報告書など、業務知識の根拠となる一次情報源。
- FAQ統合:よくある質問と回答のペアを、ベクトルDB上でひとつのナレッジとして統合・管理する手法。
FAQは特に強力です。質問文と回答文がセットになっているため、ユーザーのクエリと意味的に一致しやすく、検索精度が上がりやすい構造を持っています。
実務では、社内文書をそのまま放り込むのではなく、FAQに変換・再構成してから取り込む「FAQ化前処理」が検索精度を大きく向上させます。たとえば、長い規定書を「〇〇の場合はどうすれば良いか?」形式のQ&Aに変換してから登録するだけで、ヒット率が著しく改善されます。
メタデータと文脈抽出:「どの情報か」を正確に把握する
文書をベクトル化して検索できるようにするだけでは不十分です。「いつ作られた情報か」「どの部署向けか」「どのカテゴリに属するか」といった属性情報を適切に付与することで、検索の精度と信頼性が飛躍的に向上します。
- メタデータ:文書に紐づける属性情報(作成日時・部署・カテゴリ・バージョン・対象者など)。検索時のフィルタリングや優先度付けに活用される。
- 文脈抽出:文書の断片(チャンク)を切り出す際に、前後の文脈や見出し情報を保持することで、単体では意味が通じにくい断片を補完する処理。
文脈抽出の具体例を挙げると、「第3条の規定に従い対応すること」という一文だけでは、何の規定かわかりません。しかし、親見出し「契約解除に関するポリシー」をチャンクに付与しておくことで、LLMが正確に解釈できるようになります。
メタデータ設計のポイントは以下の通りです。
- 日時情報:古い情報より新しい情報を優先させる
- 部署・対象者タグ:質問者の属性に合わせて絞り込む
- 信頼度フラグ:確認済み・ドラフト・廃止済みを区別する
「どんな情報か」と「どういう文脈か」を両立させた設計が、ナレッジ活用の質を決定づけます。
更新容易性:ナレッジを”生きた資産”として維持する
どれほど精巧なRAGシステムを構築しても、情報が古くなれば価値は失われます。むしろ、古い情報がそのまま回答に使われることで、誤った案内を引き起こすリスクすら生じます。
- 更新容易性:ナレッジベースの情報を、低コスト・低リスクで追加・修正・削除できる設計上の特性。RAGシステムの持続的な運用に不可欠な要素。
更新容易性を高めるための実践的な設計原則を紹介します。
① 文書とIDの分離管理
文書ごとに一意のIDを付与し、内容が変わってもIDを引き継ぐことで、差分更新(変更箇所だけ再登録)が可能になります。
② 廃止フラグの活用
削除ではなく「廃止済み」フラグを立てることで、検索対象から除外しつつ、履歴として保持できます。監査や過去参照の場面で役立ちます。
③ 更新トリガーの自動化
社内の文書管理システム(SharePoint・Confluenceなど)と連携し、文書が更新されたら自動的にRAGのナレッジベースも更新される仕組みを作ることで、運用担当者の手間を最小化できます。
「作って終わり」ではなく、「育て続けられる設計」こそが、RAGを組織に根付かせる最大の鍵です。
この記事のまとめ
ナレッジ活用最適化を実現するために押さえるべきポイントを整理します。
| 観点 | 実践すべきこと |
|---|---|
| 社内文書 × FAQ統合 | 一次情報をFAQ形式に変換して取り込む |
| メタデータ × 文脈抽出 | 属性情報と前後文脈をチャンクに付与する |
| 更新容易性 | 差分更新・廃止管理・自動連携で鮮度を保つ |
社内に眠る知識は、適切な設計によって強力な”検索可能資産”に変わります。RAGは導入がゴールではなく、ナレッジを育て続けるプロセスそのものが本質です。
まずは手元の社内文書を棚卸しするところから、最適化の第一歩を踏み出してみましょう。
RAG導入専門:語彙辞典
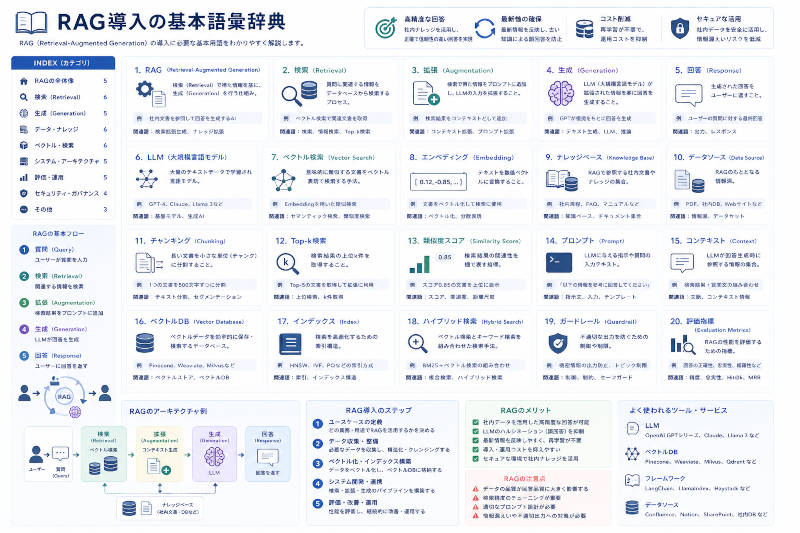
以下に、検索された知識(ナレッジ)をLLM(大規模言語モデル)へ効率的に受け渡し、実用的な回答を生成させる「ナレッジ活用最適化」の重要キーワードとその簡潔な意味を一覧で示します。
■ 1. コンテキストの最適化(情報の取捨選択と配置)
・プロンプトインジェクション(Prompt Injection):検索されたチャンクやユーザーの質問を、LLMへの指示文(プロンプト)に適切に組み込む処理。
・インコンテキストラーニング(In-Context Learning):LLMを追加学習させるのではなく、プロンプト内に参考情報(ナレッジ)を提示することで、その場限りの高度な回答を行わせる手法。
・コンテキスト圧縮(Context Compression):検索したテキストから不要な重複やノイズを削ぎ落とし、LLMに渡す情報量をコンパクトかつ高密度にする技術。
・インフォメーションルーティング(Information Routing):ユーザーの質問内容を分析し、FAQ、製品マニュアル、社内規定など、適切なナレッジソースへ自動で振り分ける仕組み。
■ 2. プロンプトエンジニアリング(指示の最適化)
・システムプロンプト(System Prompt):「あなたは人事担当です」「検索結果のみに基づいて答えてください」など、LLMの役割や回答の絶対ルールを規定する基礎指示文。
・Few-Shotプロンプト(Few-Shot Prompting):プロンプトの中に数件の「質問と理想的な回答のペア(お手本)」を含めることで、LLMの出力フォーマットやトーンを制御する手法。
・思考の連鎖 / CoT(Chain of Thought):「ステップ・バイ・ステップで論理的に考えてください」と指示し、LLMに思考プロセスを出力させることで、複雑なナレッジの処理精度を上げる手法。
■ 3. ドキュメントマネジメント(知識源の最適化)
・データクレンジング(Data Cleansing):RAGに投入する前に、PDFの文字化け修正、重複ページの削除、古いバージョンの破棄などを行い、ナレッジの「鮮度と質」を保つ前処理。
・アクセス制御 / ACL(Access Control List):ユーザーの権限(一般社員、人事、経営層など)に応じて、検索・出力できるナレッジの範囲を厳格に制限するセキュリティ機能。
・動的更新(Dynamic Update):社内規則の変更や新商品の発売に伴い、ベクトルデータベース内のナレッジをリアルタイムまたは定期的に自動同期・更新する仕組み。
■ 4. 回答生成と検証(アウトプットの最適化)
・ソース提示(Source Attribution):LLMが回答を作成する根拠となった社内文書のファイル名やページ数、URLを明記し、ユーザーが事実確認(ファクトチェック)を行えるようにする機能。
・ガードレール(Guardrails):LLMの入力と出力を監視し、不適切な表現、機密情報の漏洩、ナレッジを無視した勝手な回答(ハルシネーション)を自動で検知・遮断する検閲システム。
・トーン&マナー(Tone and Style):企業のブランドや業務の性質に合わせて、LLMの語尾(です・ます調)、専門用語の選定、回答の親しみやすさを調整・一貫させること。